
IBM Announces Granite 4.0 Tiny Preview – an Extremely Compact & Compute Efficient AI Model

As its name suggests, Granite 4.0 Tiny will be among the smallest offerings in the Granite 4.0 model family. It will be officially released this summer as part of a model lineup that also includes Granite 4.0 Small and Granite 4.0 Medium. Granite 4.0 continues IBM’s firm commitment to making efficiency and practicality the cornerstone of its enterprise LLM development. This preliminary version of Granite 4.0 Tiny is now available on Hugging Face—though we do not yet recommend the preview version for enterprise use—under a standard Apache 2.0 license. Our intent is to allow even GPU-poor developers to experiment and tinker with the model on consumer-grade GPUs. The model’s novel architecture is pending support in Hugging Face transformers and vLLM, which we anticipate will be completed shortly for both projects. Official support to run this model locally through platform partners including Ollama and LMStudio is expected in time for the full model release later this summer.
Enterprise performance on consumer hardware
LLM memory requirements are often provided, literally and figuratively, without proper context. It’s not enough to know that a model can be successfully loaded into your GPU(s): you need to know that your hardware can handle the model at the context lengths that your use case requires.
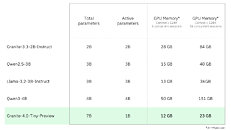
Furthermore, many enterprise use cases entail not a lone model deployment, but batch inferencing of multiple concurrent instances. Therefore, IBM endeavors to measure and report memory requirements with long context and concurrent sessions in mind. Granite 4.0 Tiny is one of the most memory-efficient language models available today. Even at very long contexts, several concurrent instances of Granite 4.0 Tiny can easily run on a modest consumer GPU.
An all-new hybrid MoE architecture
Whereas prior generations of Granite LLMs utilized a conventional transformer architecture, all models in the Granite 4.0 family utilize a new hybrid Mamba-2/Transformer architecture, marrying the speed and efficiency of Mamba with the precision of transformer-based self-attention. Granite 4.0 Tiny-Preview, specifically, is a fine-grained hybrid mixture of experts (MoE) model, with 7B total parameters and only 1B active parameters at inference time. Many of the innovations informing the Granite 4 architecture arose from IBM Research’s collaboration with the original Mamba creators on Bamba, an experimental open source hybrid model whose successor (Bamba v2) was released earlier this week.
TPU Editor’s note: an in-depth exploration of Mamba models can be found in IBM’s original article.
What’s happening next
We’re excited to continue pre-training Granite 4.0 Tiny, given such promising results so early in the process. We’re also excited to apply our learnings from post-training Granite 3.3, particularly with regard to reasoning capabilities and complex instruction following, to the new models. Like its predecessors in Granite 3.2 and Granite 3.3, Granite 4.0 Tiny Preview offers toggleable thinking on and thinking off functionality (though its reasoning-focused post-training is very much incomplete).
More information about new developments in the Granite Series will be presented at IBM Think 2025, as well as in the weeks and months to follow.

Check out Granite 4.0 Tiny Preview on Hugging Face.











